RDD는 Spark에서 데이터를 처리하고 저장하기 위한 핵심 객체로 Resilient Distributed Dataset. 직역해보면, 탄력적 분산 데이터 세트를 의미한다.
RDD의 주요 특성
- 불변성: 한번 생성되면 변경될 수 없으며 Transformation을 취하게 되면 기존 RDD가 변하는 것이 아닌 새로운 RDD가 생성된다. 이러한 불변성 덕분에 아래 특성들을 얻을 수 있다.
- 분산 처리: 불변성 덕분에 데이터의 일관성 문제 걱정 없이 데이터를 여러 노드에 분산시켜 저장하여 병렬로 처리할 수 있다.
- 내결함성: 데이터 변형 작업의 기록이 저장되며 이를 통해 노드 장애가 발생해도 데이터를 복구할 수 있다.
RDD의 생성
크게 2가지 방식을 사용한다.
- 외부 데이터 소스 로드: 파일 시스템(HDFS, S3 등), 외부 데이터베이스 또는 기타 데이터 소스(Text File, CSV 등)에서 데이터를 로드하여 RDD를 생성
- 스파크 내부 데이터 컬렉션 사용: Spark Context의
parallelize함수를 사용해 로컬 데이터 세트로 RDD를 생성
위 두 경우 모두 SparkContext를 사용해 만든다는 점을 기억해두자.
RDD의 연산
- Transformations: 기존 RDD를 기반으로 새로운 RDD를 만드는 연산이다. (map, filter, reduceByKey 등의 연산이 있다. 더 많은 내용은 필요할 때마다 도큐먼트를 보며 참고하자.)
- Actions: RDD 데이터에 대한 계산을 수행하고 결과를 반환하는 연산이다. (count, collect 등이 있다. 마찬가지로 필요할때마다 도큐먼트를 보며 참고하자.)
Lazy Evaluation
Spark가 Hadoop의 map reduce보다 빠른 이유 중 하나가 바로 lazy evaluation이다.
RDD에 Transformation을 아무리 열심히 가해도 Spark는 아무 일도 하지 않는다. 하지만 RDD에 Action을 취하는 순간부터 Spark는 DAG를 만든다. 이것이 Lazy Evalution이며 이것이 Spark가 빠른 이유이다.
RDD의 병렬 처리
RDD는 데이터를 여러 파티션이라는 더 작은 단위로 나누어 병렬 처리를 할 수 있다. 앞서 언급한 것처럼 RDD는 불변한 속성을 가지기에 이 파티션들 또한 변형이 불가능하다.
그렇기 때문에 데이터 일관성 문제 걱정 없이 수평적으로 늘려 성능을 개선할 수 있다.
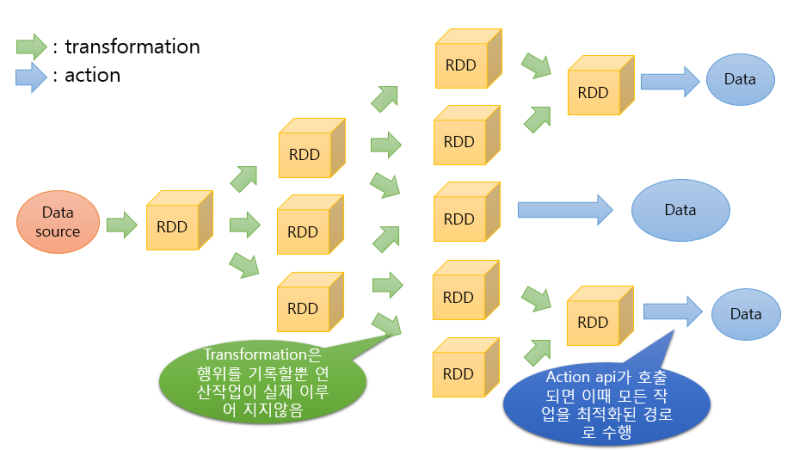
위 그림은 RDD의 전체 과정을 나타낸 그림으로 RDD에 Transformation과 Action을 취하게 된다.
이때 Transformation은 위에서 언급한 map, filter같은 연산들이며, Action은 count, collect, save 등 결과물을 rdd에서 뱉어내게 하는 것을 의미한다.
앞서 언급한 것처럼 실제 Spark가 DAG를 만드는 때는 Action을 취할 때이며, 이전까지는 Lazy하게 아무것도 안한다.
Reference
'공부 및 정리 > 데이터 엔지니어링' 카테고리의 다른 글
| [Airflow] 비트코인 일일 분 봉 데이터 파이프라인 프로젝트 (작업편) (1) | 2024.03.06 |
|---|---|
| [Airflow] 비트코인 일일 분 봉 데이터 파이프라인 프로젝트 (환경 설정편) (1) | 2024.03.06 |
| MapReduce (0) | 2024.03.06 |
| [Airflow] DAG (0) | 2024.03.04 |
| [Airflow] 개요 및 설치 방법 (0) | 2024.03.04 |



